今天的主要学习内容包括课程说明, Cuda和Gpu简介, 简单的Linux操作, 简单的Cuda编程。
简单复习几个并行化指标、MakeFile和Cuda编程内容
加速比主要是为了对比并行Gpu计算的情况下比串行Cpu计算代码速度有多大的提升, 其计算公式在下图中:
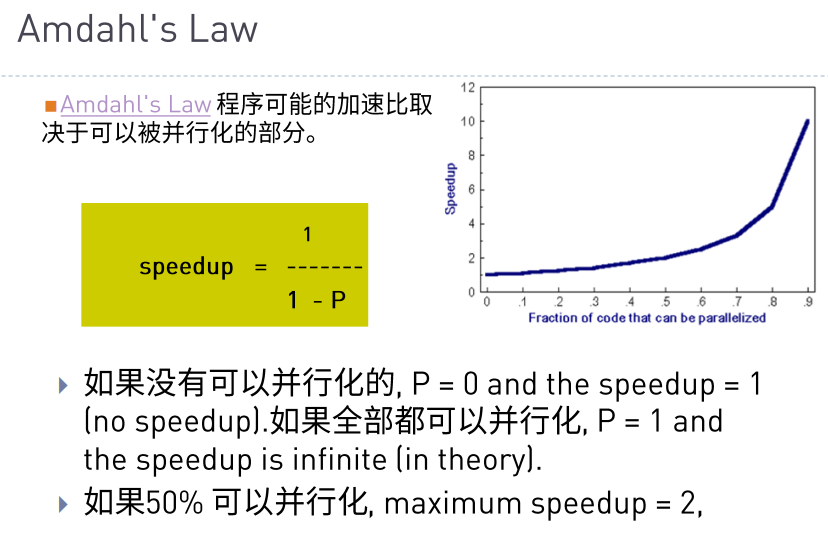
按照文字进行理解, 假定有80%的内容可以进行并行话, 那么
Speedup = 1 / (1 - 0.8) = 5
对于并行的加速比计算公式如下:

加速比是存在上限的, 根据上图我们可以知道, 当 N 越大的时候, P/N 就会越小, 也就表示分母越小, 从而加速比越大。
但是, P/N 也受到 P 的制约, 由于 S + P = 1 , 所以 S 的大小也决定着加速比的上限, 按照 p=.50 、 p=.90 、 p=.99 进行加速比计算举例, 结果如图:
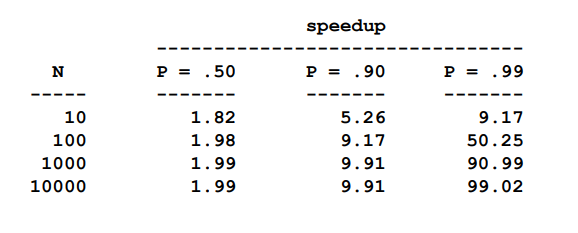
可以看到加速比是没能随着N的增加而继续增加的。
MakeFile是编译C, C++的一个文件, 按照MakeFile内的内容对部分的文件进行编译或者文件的生成。
使用 make 执行MakeFile文件。如果MakeFile内写有 Clean 等内容, 可以使用 make clean 执行清理操作
从上面的代码可以看出, 临时变量写在最开始, 使用的时候使用 $() 进行包裹指代, 而 clean 应该写在最后, 以免影响 make 指令的执行顺序。
.PHONY : clean 中应该关注 .PHONY 这一项, 因为这个关键字主要是为了避免指令和文件名冲突, 假如目录下同样存在 clean 文件, 那么 make clean 在没有 .PHONY 的情况下会报错(可以自行尝试)。
另外需要注意, 换行之后尽量使用 TAB 进行缩进。
课件中同样提供了Cuda编译使用的一个示例:
可以看到基本的内容和上面是一样的, 只是编译的文件从 xxx.c 变成了 xxx.cu, 编译指令从 gcc 变成了 nvcc 。其他并无不同。
课程内容比较多, 就简单挑着自己的理解去写了。
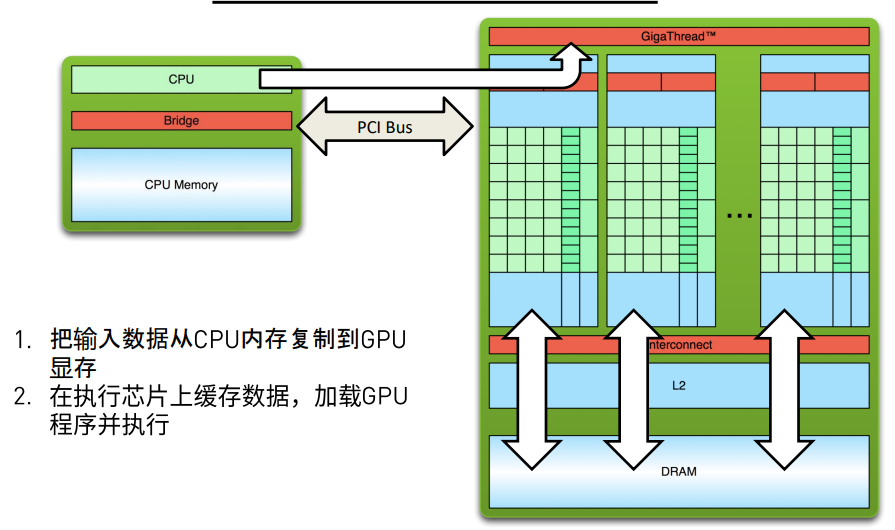
在进行代码之前, 先对cuda的数据传输进行一定的了解, 由于是操作GPU进行计算, 所以主要的数据其实都应该导入到GPU的缓存中进行, 包括部分指令也会在GPU上操作。
所以可以看到如下图所示:
在运行执行结束之后, 运算结果讲重新搬回CPU中, 进行下一步的操作。如下图:
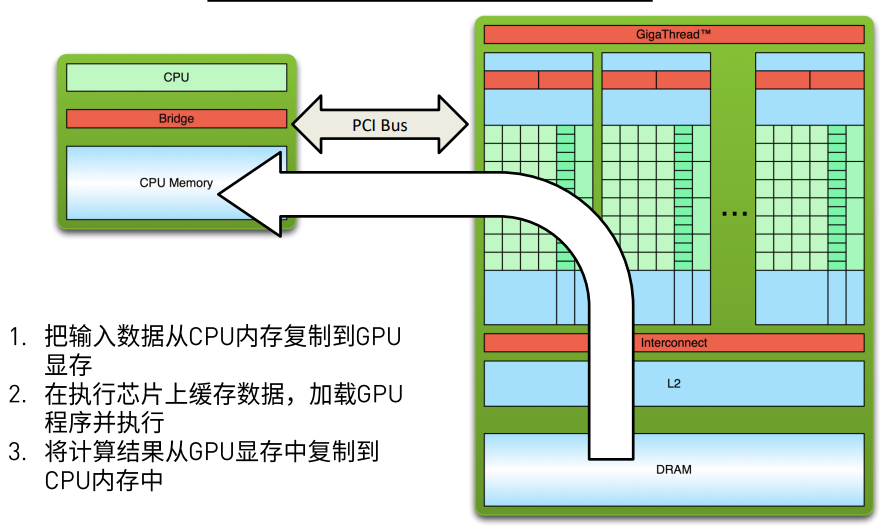
所以这几步操作会体现在代码中会有一定的复制、转移的操作, 同时内存申请和释放也会比单纯的串行程序使用更多一步GPU的内存申请和释放。
在CUDA编程中, 程序执行和调用的位置会有两个, 一个是CPU(也称Host), 另外一个则是GPU(也称Device)。函数模式, 则一共有三种, 分别是: __device__, __global__, __host__。先看下图:
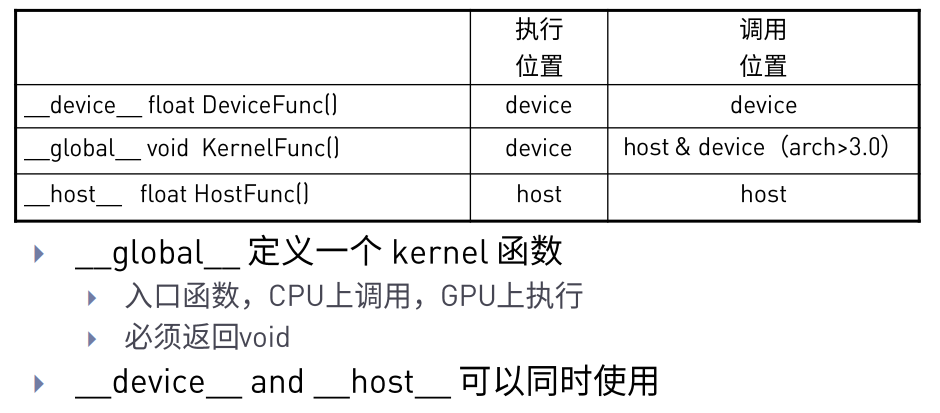
根据上图我们可以看到 __device__ 很明显应该是在GPU设备中被调用然后执行, 而 __global__ 则是从CPU到GPU的过度函数, 甚至就是使用GPU的函数, 而__host__则是单纯的CPU函数, 也就是常规的C函数。
在上面的MakeFile中已经进行了简单的差异描述, 但是, 为了保证编译后的文件的可用, GPU编译比CPU编译多了一个参数, 通常是为了指定架构, 例如 arch = 60, 由于走神, 这里没太懂, 所以放一下PPT图片:

主要是三种模式, 每种模式都有不同的显示内容:
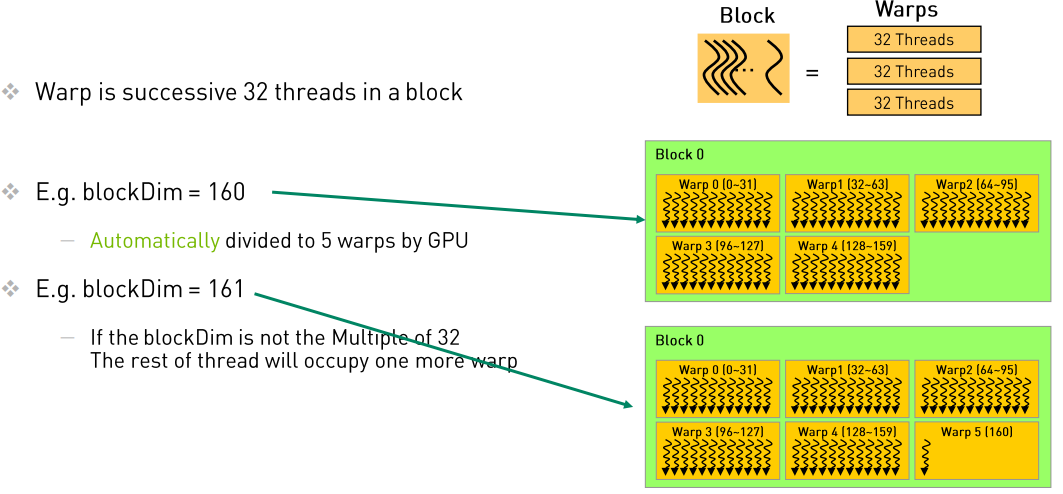
在线程调度这一部分, 主要有三个层级Grid, Block, Thread, 其中Thread是常见的线程, 而Block是为了管理Thread而出现的, 在常规的GPU core中, 一个Block通常拥有32个Thread。
而Grid则是管理Block的, 在线程层次和线程调度入门中, 个人认为有两个地方较为重要:一是线程的组织结构, 二是线程索引。
从Thread开始, 首先我们应该注意, Thread会被wrap调度器以32个为一组, 组成一个wrap, 但是Block才是管理thread的, 所以Block_si ze应该是以32作为倍数, 比如32或者64, 以求最大化使用算力。
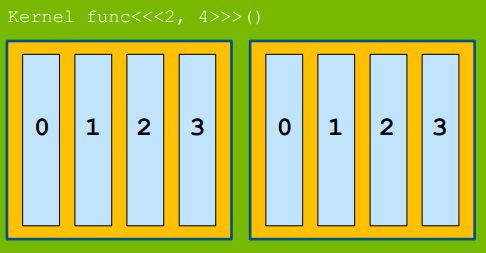
而接下来, 由Thread组成了Block, 在基础的情况中中, <<<BLOCKS,BLOCK_SIZE>>>表示的是申请BLOCKS个Block, 每个Block内部有 BLOCK_SIZE个Thread, 这时候情况较为简单, Grid的应该是一个1XBLOCKS的长矩阵, 每个Block也是一个1xBLOCK_SIZE的长矩阵。
接下来是由dim3构成的高纬度线程模型, 举例来说, 我们可以由dim3 grid_size(3,3,3)定义出一个3x3x3的三维矩阵, 在这个矩阵中, 一共有27个Block, 此时, 这个Grid的维度, 也就是gridDim.x、gridDim.y、gridDim.z三个值, 均为3, 也就是blockIdx的x、y、z最大值均为2(下标从0开始)。 在这样时候, 你可以把整个Grid视为一个常见的3x3的魔方, 魔方上面的每一个方块都是一个Block。
而我们再定义一个dim3 block_size(3,3,3)之后, 每个Block也变成了一个3x3的小魔方, 此时每个Thread是组成这个魔方的一份子。
然后使用<<<grid_size,blocksize>>, 我们得到的线程总数应该是729个(是 3x3x3 * 3x3x3的结果)。
先看一句求线程索引的代码(注意, 此时cuda的调度维度是<<<BLOCKS,BLOCK_SIZE>>>):
其中, Dim 表示的是维度, 例如Block是一个10x10的矩阵, 那么BlockDim.x和BlockDim.y都应该是10。
而Idx则表示索引, 也就是所在位置。例如Grid组成了一个5x4的矩阵, 而某个Block位于(3, 2)位置, 那么BlockIdx.x是2, BlockIdx.y是3。
所以我们再来看n的求得过程, 其中blockDim.x * blockIdx.x作用是求得前面的Block一共占了多少个位置, 然后再加上在Block内部ThreadIdx.x 来求得自己所在位置。
接下来重新读Idx的那段话, 一个很奇怪的地方在于, X是2, 而Y是3, 这里应该这样思考, X表示的是横坐标, 但是放到矩阵上, 表示的其实是第几列, 而Y则相反, 表示的是纵坐标, 在矩阵上表达的是第几行, 所以在求一个线程在一个巨型矩阵中的位置的时候, 列坐标应该是用
而行坐标则是应该用
接下来是一个Cuda的向量相加的代码示范:
为了更清楚的对比, 在下面放上了单纯CPU的向量相加的写法:
这篇博客的完成日期时冬令营已经结束, 所以内容是超过第一天上课所讲的。