本系列具体介绍可以参见基础篇。这篇是系列第二篇, 篇幅相较于基础篇会比较短, 因为 Nemo 真的是一个很好用的库。
该篇主要分为三个部分:
<a id="intro"></a>
ASR:自动语音识别技术, Automatic Speech Recognition 的缩写, 其目的是将人的语音转化为文字。在各大社交软件以及输入法中已经是普遍可见的应用。
以 Sky Hackthon 比赛理念出发, 比赛通常是构建一个可以应用于实际生活中的 AI 小工具, 那么日常生活中, 最为常见的沟通手段肯定就是使用对话交流。可以说, ASR 技术可以说是构建 AI应用中必不可少的一环。
在 Sky Hackthon 的比赛中, 通常使用 Nemo 进行 ASR 模块的构建, 从官网页面我们可以得知:
NVIDIA NeMo 是一个框架, 用于借助简单的 Python 界面构建、训练和微调 GPU 加速的语音和自然语言理解 (NLU) 模型。使用 NeMo, 开发者可以创建新的模型架构, 并通过易于使用的应用编程接口 (API), 在 NVIDIA GPU 中的 Tensor Core 上使用混合精度计算对其进行训练。
借助 NeMo, 您可以构建用于实时自动语音识别 (ASR)、自然语言处理 (NLP) 和文本转语音 (TTS) 应用(例如视频通话转录、智能视频助理以及医疗健康、金融、零售和电信行业的自动化呼叫中心支持)的模型。
而正如其宣传的那样, Nemo 的使用其实真的很简单很简单, 做好数据收集和模型训练, 在 Sky Hackthon 一定能拿到好的结果!
<a id="data"></a>
机器学习与深度学习的相关人士肯定都听过一句话:数据决定上限, 模型抬高下限。因此在 ASR 篇中, 重点会讲如何收集与处理数据集, 保证收集到足量足质的数据集。
数据基本要求:单声道、WAV格式、44100采样率、普通话、内容完整、尽量无噪声。
数据额外要求:数据越多越好、发音尽可能多元化(主要指年龄、性别)。
这里提供几个方案供大家参考, 视自己情况选择方案进行数据收集。
方案一:自己录制。 自己参赛, 自然应该 Push 自己, 队伍内成员对语音内容反复录制3-5条并不会导致数据过分拟合, 特别是每个人语速、语调都是可以人为控制进行变换的, 可以视为单独录制的。同时, 如果队伍成员内有喜欢配音的小伙伴, 那我只能说, 声优都是怪物, 完全可让他们多录一点。 方案优点:质量有保障、来源很稳定、重复录制可以获取大量数据。 方案缺点:音色单一、数据内容同质性高、可能过拟合。
方案二:呼朋唤友。 可以呼唤课题室内的小伙伴, 或者是同班同学, 每个人来帮忙录制一句, 积少成多, 也可变成非常大量的数据集。当然, 对小伙伴们要求就不能太高, 尽量提前做好准备工作, 比如调整好设备, 设置好参数, 让小伙伴们过来简单说两句话就ok, 大家一般都是不会拒绝的。如果是要线上通知朋友, 一定要提前做好教程, 告知如何录制有效的数据集, 避免白费功夫。 方案优点:质量可能略低于方案一, 但是相对有保证、音色更加多样, 过拟合可能性降低。 方案缺点:可能数量不足、适合线下场景、需要一定社交与沟通能力。
方案三:撒钱大法。 该方案需要借助QQ, 适合有群管理的, 或者有很多很多群的, 又或者有诸多线上朋友的同学, 使用QQ语音红包, 可以让大家为了抢红包而为你发送语言, 而你只需要提前打开 QQ 保存音频的文件夹(位于
QQ存档目录/QQ号/Audio), 然后就可以等着收文件了! 方案优点:收集速度快、收集数量大且音色丰富。 方案缺点:需要消耗一定的金钱、可能被群管理员移出群聊、质量低, 需要二次过滤保证可用性。 使用提示:1.收获的文件名称均为乱码, 需要根据时间排序后提取可能的文件, 然后进行挨个过滤, 建议做好准备统一处理2.收获的文件并非 WAV 格式, 也非 44100 的采样率, 可以考虑使用格式工厂进行批量转换。3.如果录音的人太快, 可能录制到开始时 滴 的一声, 如果比较熟可以考虑重新录, 不太熟只能废掉了。4.录制过来的文件可能存在大量的方言、或者带有底噪的, 前者建议直接删除, 后者请视情况而定。方案四:API合成。 可以使用诸如 百度、讯飞、腾讯等的 API 接口, 生成不同的 语音内容, 然后使用 ffmpeg 进行格式转换之后加入训练。该方案来自于 恺 在第六届比赛中的帮助, 所以请说:谢谢你, 恺! 方案优点:数据来源稳定、质量较好。 方案缺点:需要一定的 Coding 能力和文档阅读能力、反复使用的时候可能需要花费小额金钱购买、需要格式转换。
关于 ASR 数据收集的一些小想法:
- 必须人工复核:建议全部的数据不论从何渠道收集而来, 尽可能的人工听过一遍, 以此来保证数据集质量, 避免训练的时候内容白费。
- 不能吹毛求疵:适当的噪音一定是可以接受的, 可以考虑现实中, 我们想要的是尽可能的听清对方所说的话, 但是我们并不能要求对方一定是在完全无噪声的情况下说话, 所以只要话的主体是清晰可见的, 我们就不应该因为底噪而抛弃数据。
相比于数据收集, 数据的处理要简单很多, 根据时间上的顺序来讲, 数据处理分为以下几个步骤:
- 人工检查: 这里人工检查主要是去听数据, 确定每一条的数据都没有太大问题, 比如没有过强的方言口音、没有特别大的噪声、没有错误的发音内容等等。
- 格式统一: 这一步是保证数据一定要符合数据训练时候的格式要求, 单声道、格式为 WAV、采样率为44100。 对于格式要求, 可以使用 ffmpeg 或者 格式工厂进行统一的批量转换。
- 切分数据: 在完成格式统一后, 我们就拥有了全量可用的数据集, 然后进行接下来要进行训练集和验证集的切分, 通常而言, 80/20 的比例或者 90/10 的比例作为训练集与验证集的切分。提示:可以给每条语音都保留至少一条的测试集, 用于最后模型的验证。
- 制作标注: 使用自己的 Code 能力, 为每个处理好的音频进行数据标注, 其主要方式是使用
librosa包获取时长, 并根据你自己的方式确定语音内容(比如使用不同文件夹表示不同的语音内容), 然后写入标注文件中。 具体代码请自行发挥, 这里不会提供。
在完成上面步骤之后, 数据就充分可用了, 将接下来进入模型训练的环节。
<a id="model"></a>
比赛官方提供的 Notebook 足以完成基础的训练, 以下操作是在基础训练之上, 保证 ASR 部分有足够的准确率。
当准备好数据集并放入指定位置之后, 我们就要准备训练了, 在这里主要讲解如何更换一个可用的模型进行训练。
- 步骤一: 确定 Nemo 版本。 在不同版本的 Nemo 中, 存在不同的可用模型, 比赛时, 可用和 YiPeng 老师确认, 是否可更换 Nemo 的版本, 如果可更换, 操作性就大了很多。但是往往不推荐新人更换版本, 因为这会带来不可知的环境冲突, 建议基础薄弱的同学跳过此步骤。
- 步骤二:确定可用模型。 在这里, 我直接无偿提供一个方法, 方便确定当前可用版本下的全部模型:
nemo_asr.models.EncDecCTCModel.list_available_models(), 该方法可获取到当前版本全部的可用的 ASR 模型。 - 步骤三:挑选模型。 根据步骤二中得到的已知模型, 我们可用去 NGC (需要登录)上挑选一个更好的基础模型。
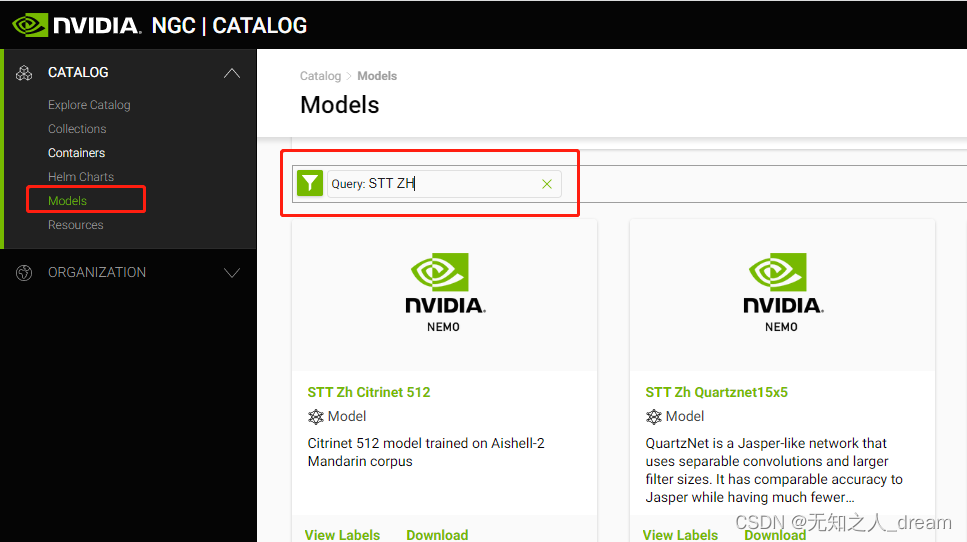 其中 STT 表示 Speech To Text 也就是 ASR 模型, 而 Zh 表示 中文模型。点击模型以后可以看到模型的基础准确率、模型调用指令等内容。根据之前已知的 Nemo 版本和多方面因素, 我们可以从中挑选一个模型作为我们的训练使用。
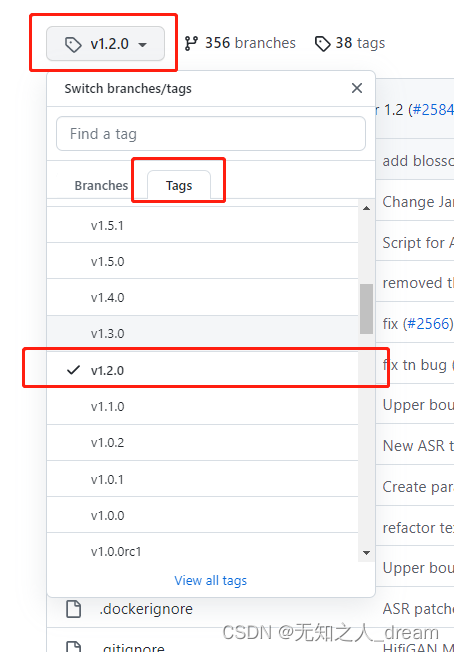
其中 STT 表示 Speech To Text 也就是 ASR 模型, 而 Zh 表示 中文模型。点击模型以后可以看到模型的基础准确率、模型调用指令等内容。根据之前已知的 Nemo 版本和多方面因素, 我们可以从中挑选一个模型作为我们的训练使用。 - 步骤四:配置文件 在挑选好模型以后, 距离训练就只有最后一步了:为模型准备配置文件。配置文件我是通过 Nemo 的 Github 仓库进行寻找的, 得益于其良好的项目结构, 我们只需要确定 Nemo 的版本, 就可以打开对应的代码历史, 然后进入 Example 文件夹进行查阅, 然后修改一些对应参数即可使用。(小提示, 默认的 quartznet 修改 citrinet 是非常简单的。)
- 步骤五:训练。 这里其实不需多言, 使用 比赛直接的脚本即可, 当然, 自己可以根据实际情况适当调整一些超参数, 比如训练轮次、学习率等。
验证的思路其实比较简单:使用代码跑一遍全部的数据集, 看看有多少的数据能拿到 1 分的满分, 如果绝大部分数据都无法拿到 1分, 我们重新检查数据集, 确定数据集毫无问题之后重新训练即可。
但是, 当只有小部分无法拿到 1 的满分的时候, 一般都是数据上出现问题, 从我个人经历出发, 分为以下情况:
- 数据标注有误:这是标注的数据和实际的语音内容存在差别导致的, 检查一下该文件位于训练还是验证, 如果位于训练集, 那与之相关的训练内容可能都会存在问题, 如果都存在问题, 可能就得重新跑了。
- 数据存在干扰:比如口音、噪声等干扰了语音识别的效果, 如果只是零星存在, 那对于最终结果基本没有影响。
- 数据毫无问题:用以数据如果干净且无其他问题, 但是测试结果存在问题, 那么可能是以下三个原因:数据量不充足、模型训练不够拟合、选择的模型存在问题。
总结而言:使用 Nemo 训练比较省心, 只要准备好数据, 挑选正确的模型, 就可以完成一次良好的训练。
得益于使用 Nemo, ASR 的整体流程相对简单, 更多的时间还是在收集数据与处理数据上, 因此, ASR 部分的完全可以由一个人单独负责全部, 其他人根据其指挥进行一定的数据收集协助即可。毕竟数据收集环节多一个人多一份力。